Python 实现的 DSA 快速排序
快速排序
顾名思义,快速排序是最快的排序算法之一。
快速排序算法取一个值数组,选择其中一个值作为“枢轴”元素,并移动其他值,使较小的值位于枢轴元素的左侧,较大的值位于其右侧。
在本教程中,我们选择数组的最后一个元素作为枢轴元素,但我们也可以选择数组的第一个元素,或者数组中的任意元素。
然后,快速排序算法对枢轴元素左右两侧的子数组递归地执行相同的操作。这一过程持续到数组排序完成。
递归是指函数调用自身。
在快速排序算法将枢轴元素置于左侧为较小值子数组、右侧为较大值子数组之间后,该算法会调用自身两次,以便快速排序再次对左侧子数组和右侧子数组运行。快速排序算法会持续调用自身,直到子数组太小而无法排序。
该算法的描述如下:
工作原理:
- 选择数组中的一个值作为枢轴元素。
- 对数组的其余部分进行排序,使小于枢轴元素的值位于左侧,较大的值位于右侧。
- 将枢轴元素与较大值的第一个元素交换,使枢轴元素位于较小值和较大值之间。
- 对枢轴元素左右两侧的子数组执行相同的操作(递归)。
手动运行
在编程语言中实现快速排序算法之前,让我们先手动对一个短数组进行排序,以便理解其原理。
第 1 步:我们从一个未排序的数组开始。
[ 11, 9, 12, 7, 3]
第 2 步:我们选择最后一个值 3 作为枢轴元素。
[ 11, 9, 12, 7, 3]
第 3 步:数组中的其余值都大于 3,必须位于 3 的右侧。将 3 与 11 交换。
[ 3, 9, 12, 7, 11]
第 4 步:值 3 现在处于正确的位置。我们需要对 3 右侧的值进行排序。我们选择最后一个值 11 作为新的枢轴元素。
[ 3, 9, 12, 7, 11]
第 5 步:值 7 必须位于枢轴值 11 的左侧,而 12 必须位于其右侧。移动 7 和 12。
[ 3, 9, 7, 12, 11]
第 6 步:将 11 与 12 交换,使较小的值 9 和 7 位于 11 的左侧,而 12 位于其右侧。
[ 3, 9, 7, 11, 12]
第 7 步:11 和 12 处于正确的位置。我们在 11 左侧的子数组 [ 9, 7] 中选择 7 作为枢轴元素。
[ 3, 9, 7, 11, 12]
第 8 步:我们必须将 9 与 7 交换。
[ 3, 7, 9, 11, 12]
现在,数组已排序完成。
运行下面的模拟程序,查看上述步骤的动画演示:
在 Python 中实现快速排序
要编写一个能够将数组不断分割为更小子数组的 'quickSort' 方法,我们需要使用递归技术。这意味着 'quickSort' 方法必须能够自我调用,分别处理基准元素左侧和右侧的新子数组。点击此处了解更多关于递归的知识。
要在 Python 程序中实现快速排序算法,我们需要:
- 待排序的值数组
- 能自我调用的 quickSort 方法(递归),当子数组长度大于 1 时继续分割
partition方法,用于接收子数组、调整元素位置、将基准元素交换到正确位置,并返回下一次子数组分割的索引位置
最终实现的代码如下:
实例
在 Python 程序中使用快速排序算法:
def partition(array, low, high):
pivot = array[high]
i = low - 1
for j in range(low, high):
if array[j] <= pivot:
i += 1
array[i], array[j] = array[j], array[i]
array[i+1], array[high] = array[high], array[i+1]
return i+1
def quicksort(array, low=0, high=None):
if high is None:
high = len(array) - 1
if low < high:
pivot_index = partition(array, low, high)
quicksort(array, low, pivot_index-1)
quicksort(array, pivot_index+1, high)
mylist = [64, 34, 25, 5, 22, 11, 90, 12]
quicksort(mylist)
print(mylist)
快速排序时间复杂度
快速排序的最坏情况是 \(O(n^2) \)。这是指在每个子数组中,枢轴元素要么是最高值,要么是最低值,这会导致大量的递归调用。对于我们上面的实现,当数组已经排序时,就会出现这种情况。
但平均而言,快速排序的时间复杂度实际上只有 \(O(n \log n) \),这比我们之前研究过的其他排序算法要好得多。这就是快速排序如此受欢迎的原因。
在下文中,您可以看到在平均情况下,快速排序的时间复杂度 \(O(n \log n) \) 相比之前的时间复杂度为 \(O(n^2) \) 的冒泡排序、选择排序和插入排序算法有了显著改善:
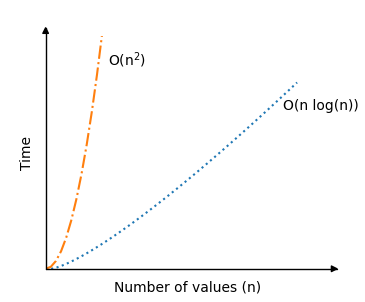
快速排序算法的递归部分实际上是平均排序场景如此之快的原因,因为对于枢轴元素的良好选择,每次算法调用自身时,数组都会大致均匀地分成两半。因此,即使值数量 n 翻倍,递归调用的次数也不会翻倍。